Browse Source
Clusterviz

12 changed files with 21 additions and 17 deletions
+ 16
- 17
R/clusterviz.R
View File
|
||
| 5 | 5 |
|
| 6 | 6 |
|
| 7 | 7 |
|
| 8 |
|
|
| 9 | 8 |
|
| 10 | 9 |
|
| 10 |
|
|
| 11 | 11 |
|
| 12 | 12 |
|
| 13 | 13 |
|
| 14 |
|
|
| 15 |
|
|
| 16 |
|
|
| 17 |
|
|
| 18 |
|
|
| 19 |
|
|
| 14 |
|
|
| 15 |
|
|
| 16 |
|
|
| 17 |
|
|
| 18 |
|
|
| 19 |
|
|
| 20 |
|
|
| 20 | 21 |
|
| 21 | 22 |
|
| 22 |
|
|
| 23 |
|
|
| 24 |
|
|
| 23 |
|
|
| 24 |
|
|
| 25 |
|
|
| 26 |
|
|
| 27 |
|
|
| 28 |
|
|
| 29 |
|
|
| 25 | 30 |
|
| 26 |
|
|
| 27 |
|
|
| 28 |
|
|
| 29 | 31 |
|
| 30 |
|
|
| 31 | 32 |
|
| 32 | 33 |
|
| 33 | 34 |
|
| 34 | 35 |
|
| 35 |
|
|
| 36 |
|
|
| 37 |
|
|
| 36 |
|
|
| 38 | 37 |
|
| 39 | 38 |
|
| 40 | 39 |
|
+ 5
- 0
README.md
View File
|
||
| 202 | 202 |
|
| 203 | 203 |
|
| 204 | 204 |
|
| 205 |
|
|
| 206 |
|
|
| 207 |
|
|
| 208 |
|
|
| 209 |
|
|
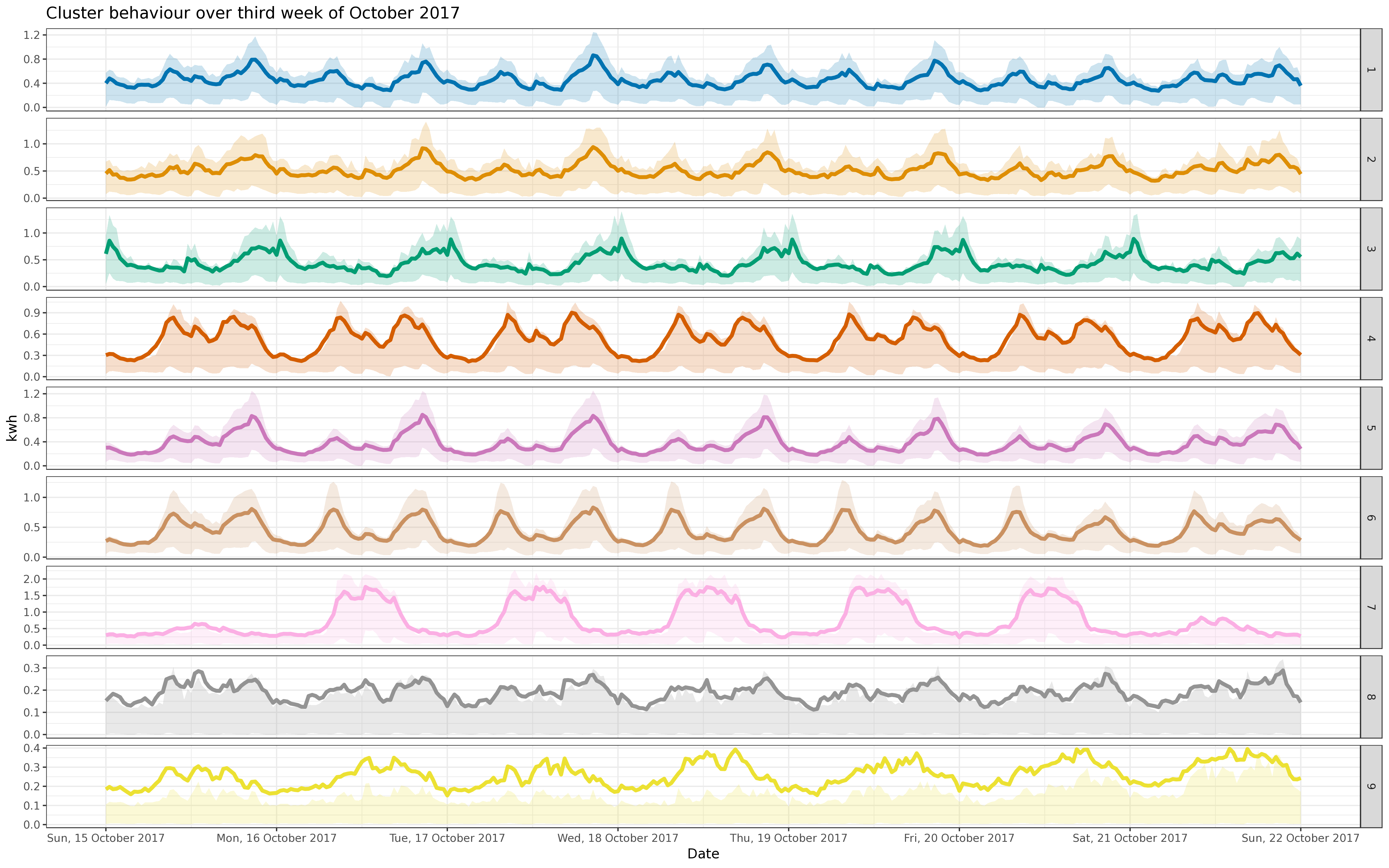
BIN
img/all_fix_5k.png
View File
{kind=link}
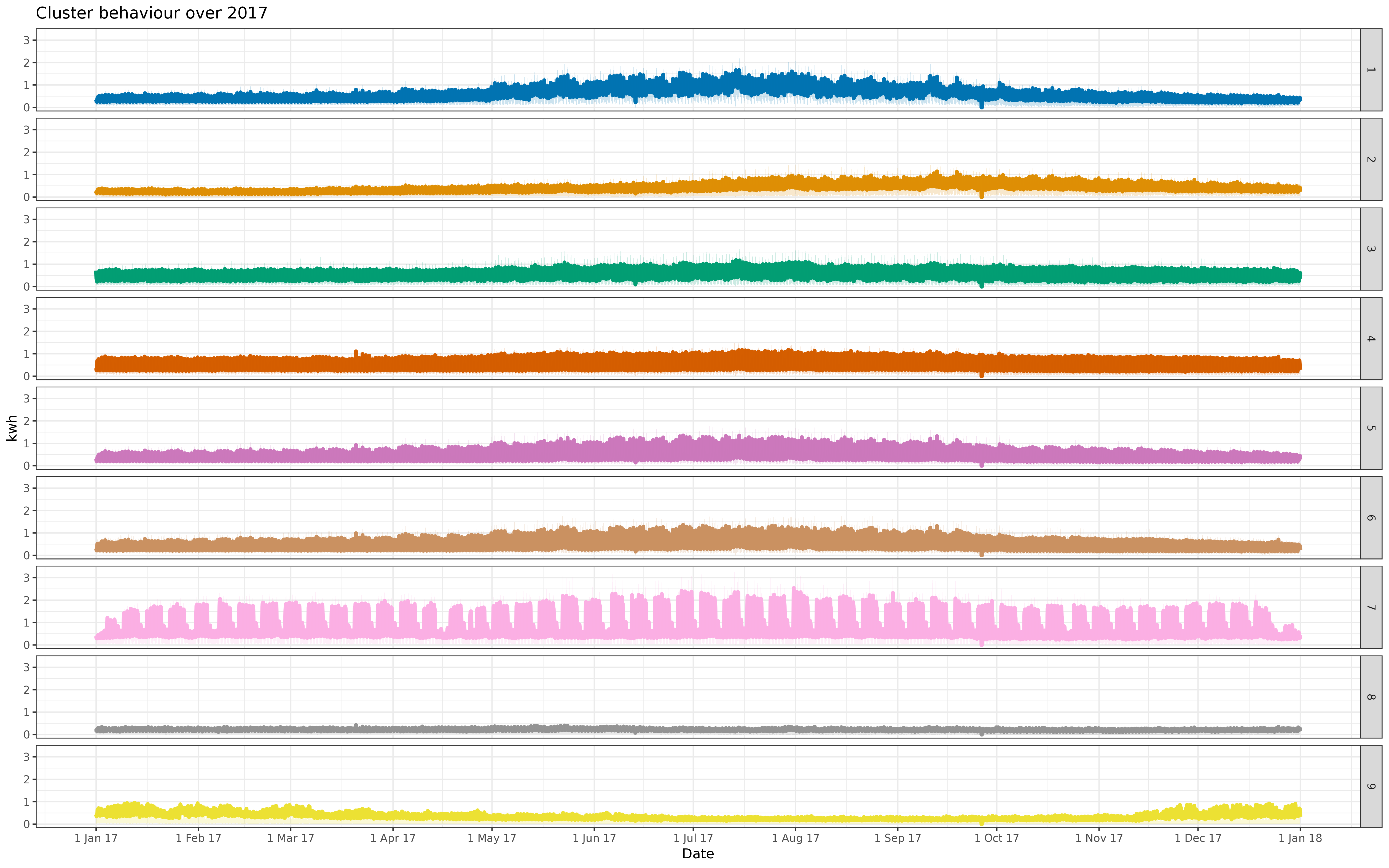
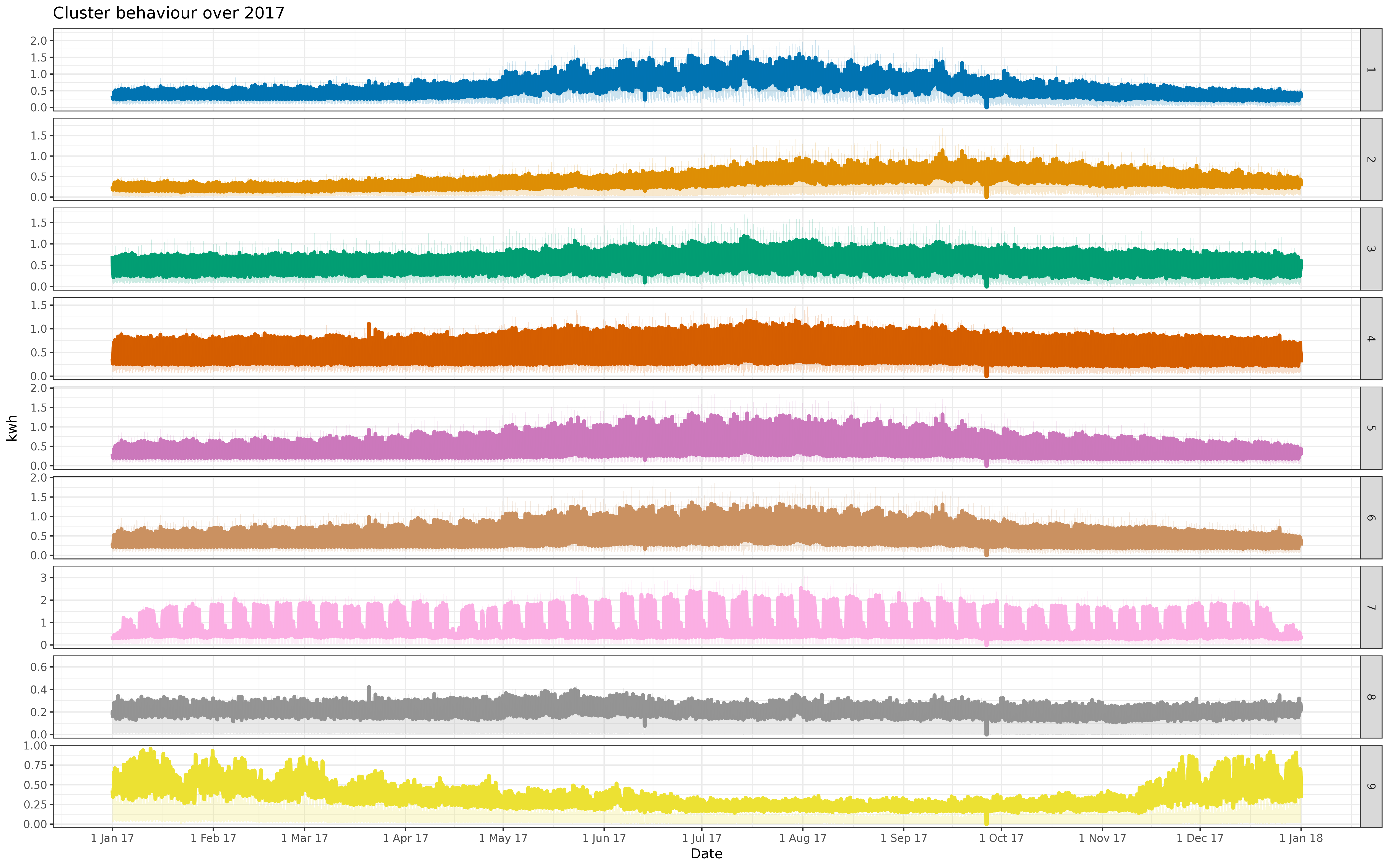
BIN
img/all_fre_5k.png
View File
{kind=link}
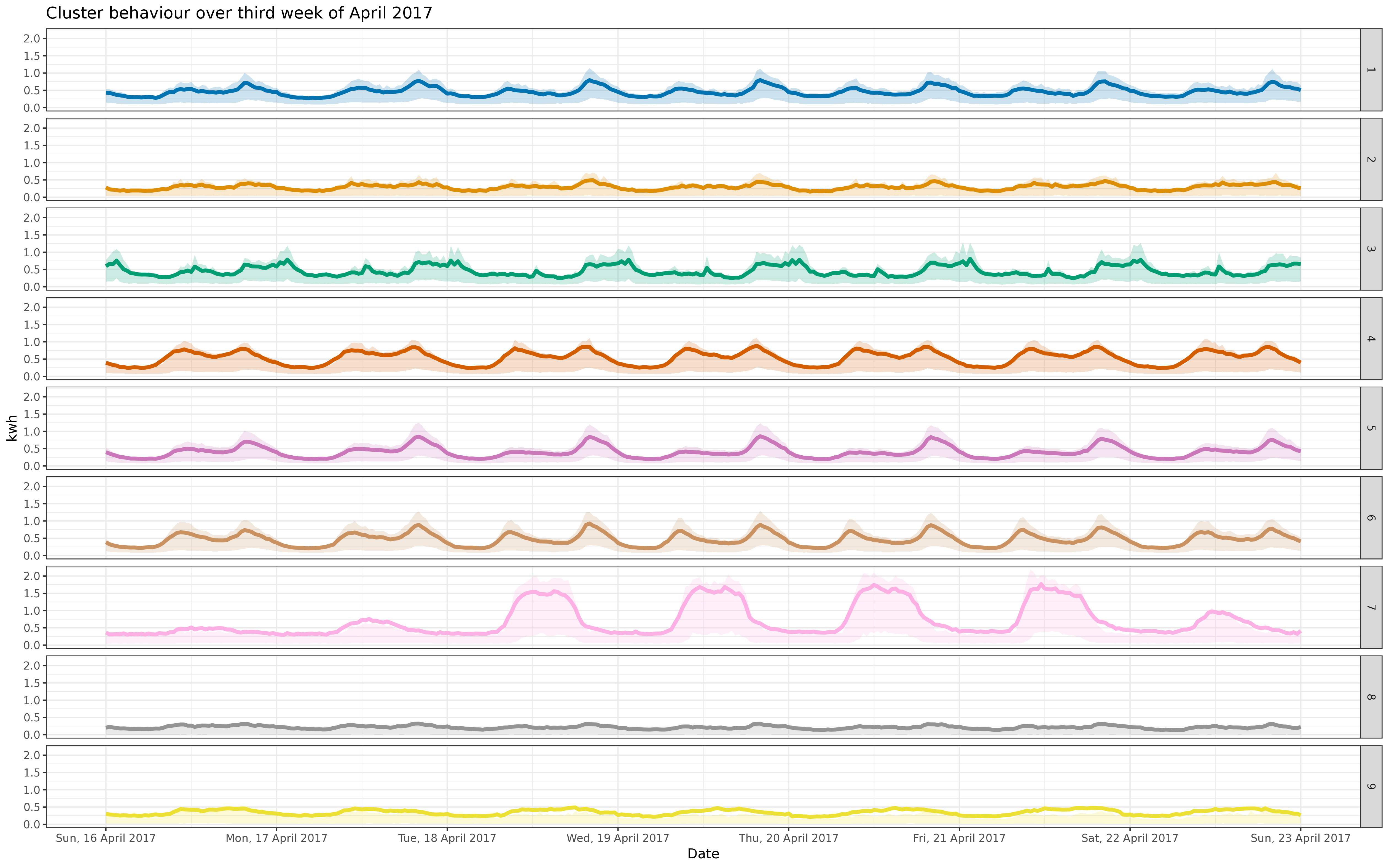
BIN
img/apr_fix_5k.png
View File
{kind=link}
BIN
img/apr_fre_5k.png
View File
{kind=link}
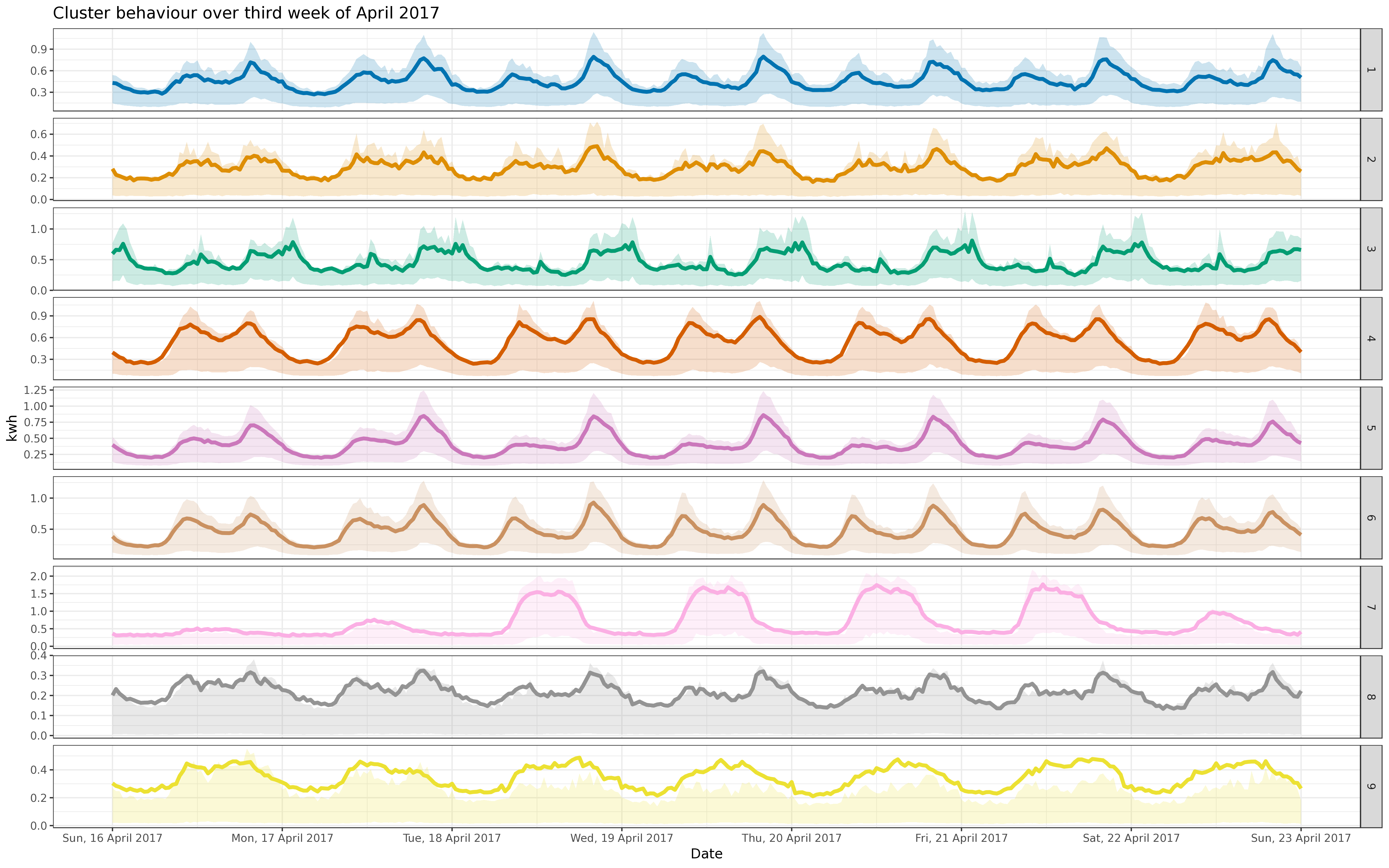
BIN
img/jan_fix_5k.png
View File
{kind=link}
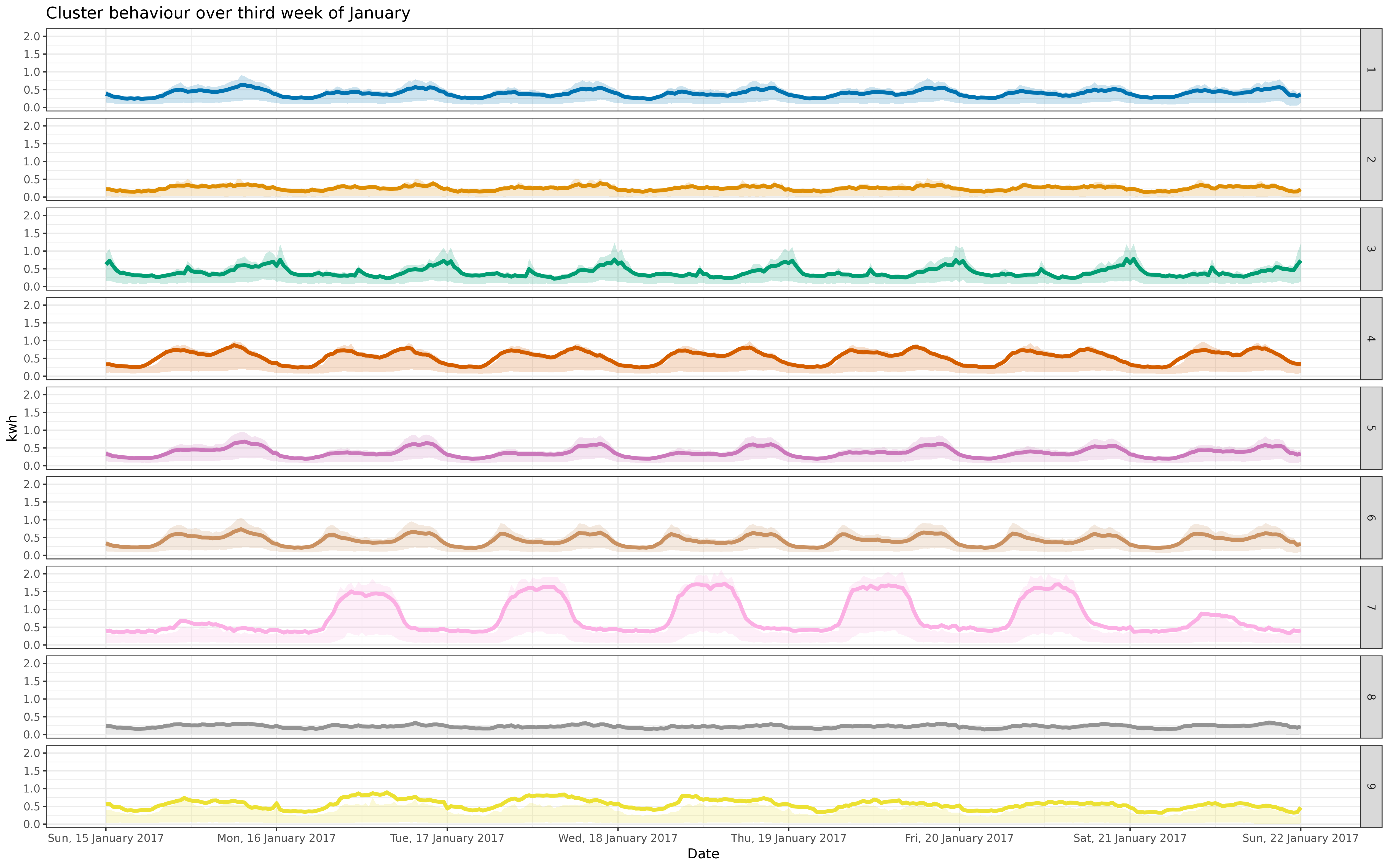
BIN
img/jan_fre_5k.png
View File
{kind=link}
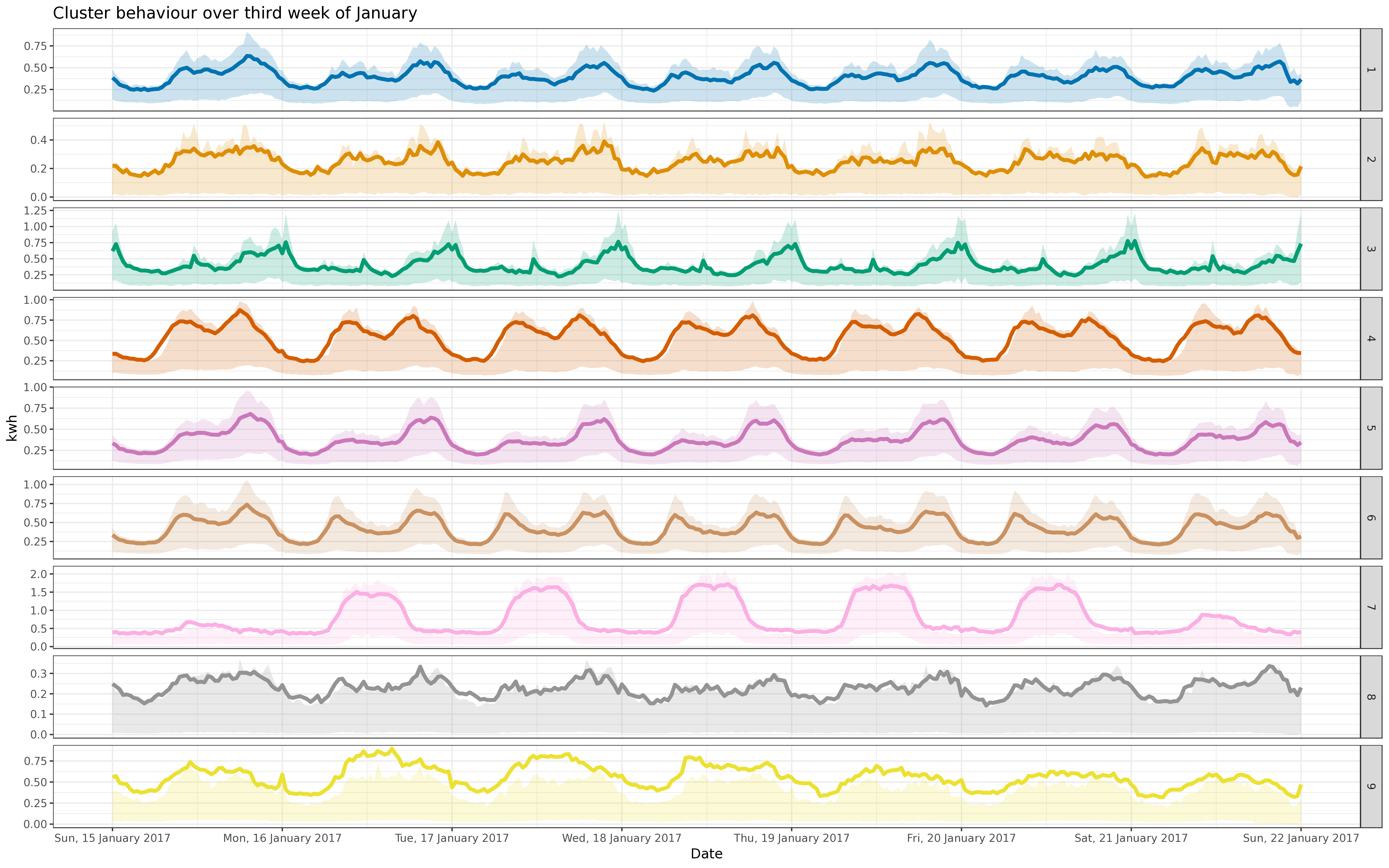
BIN
img/jul_fix_5k.png
View File
{kind=link}
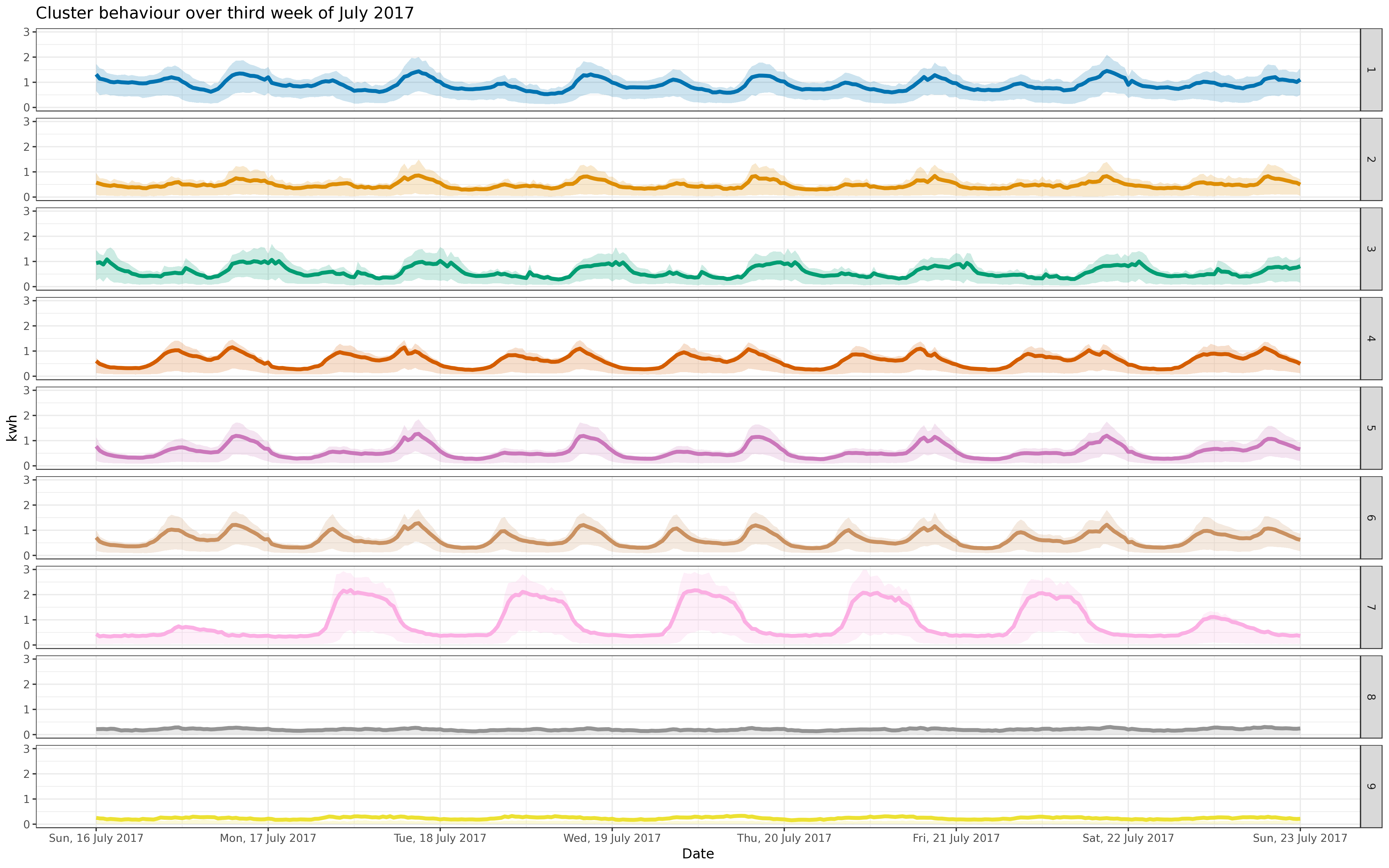
BIN
img/jul_fre_5k.png
View File
{kind=link}
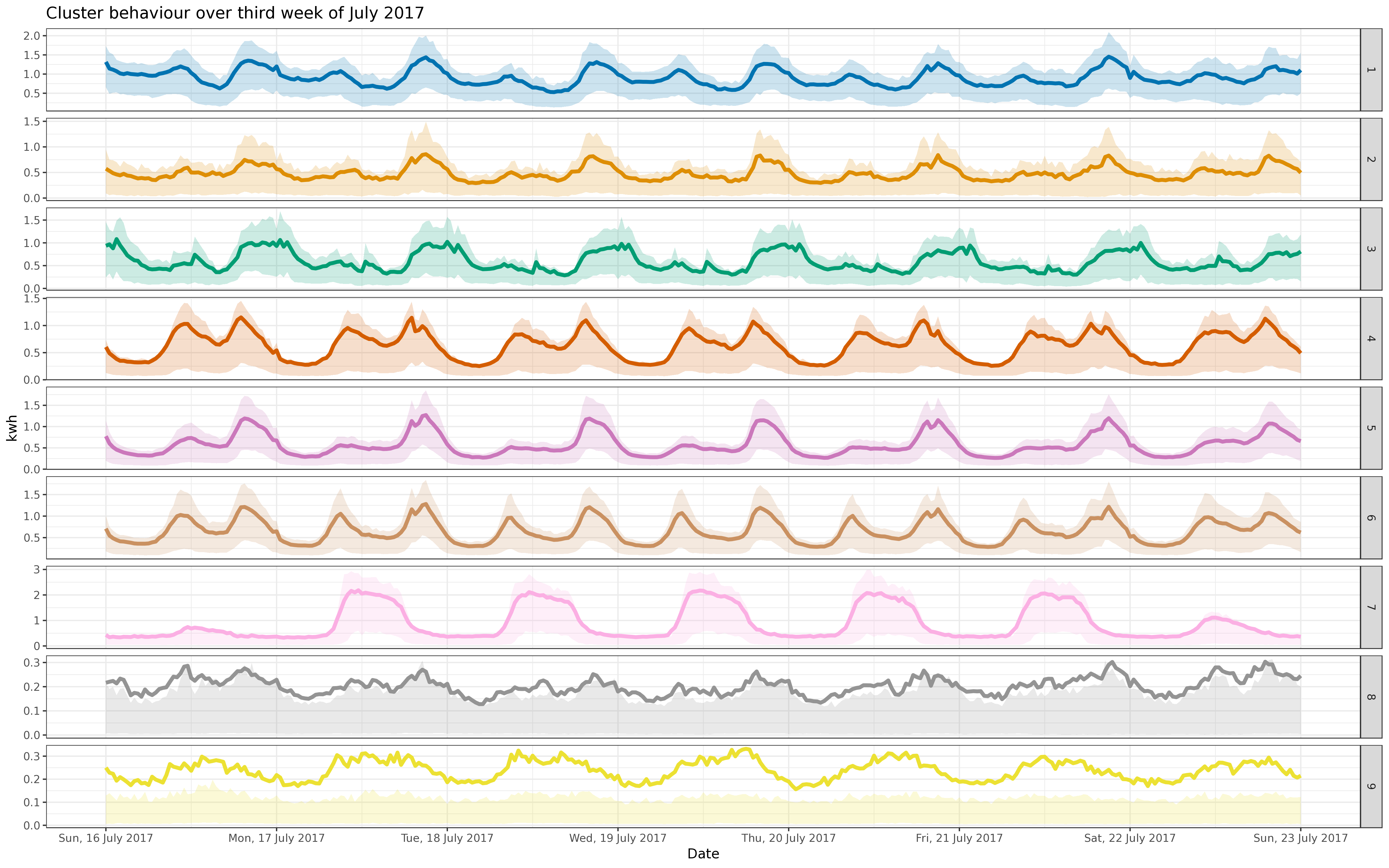
BIN
img/oct_fix_5k.png
View File
{kind=link}
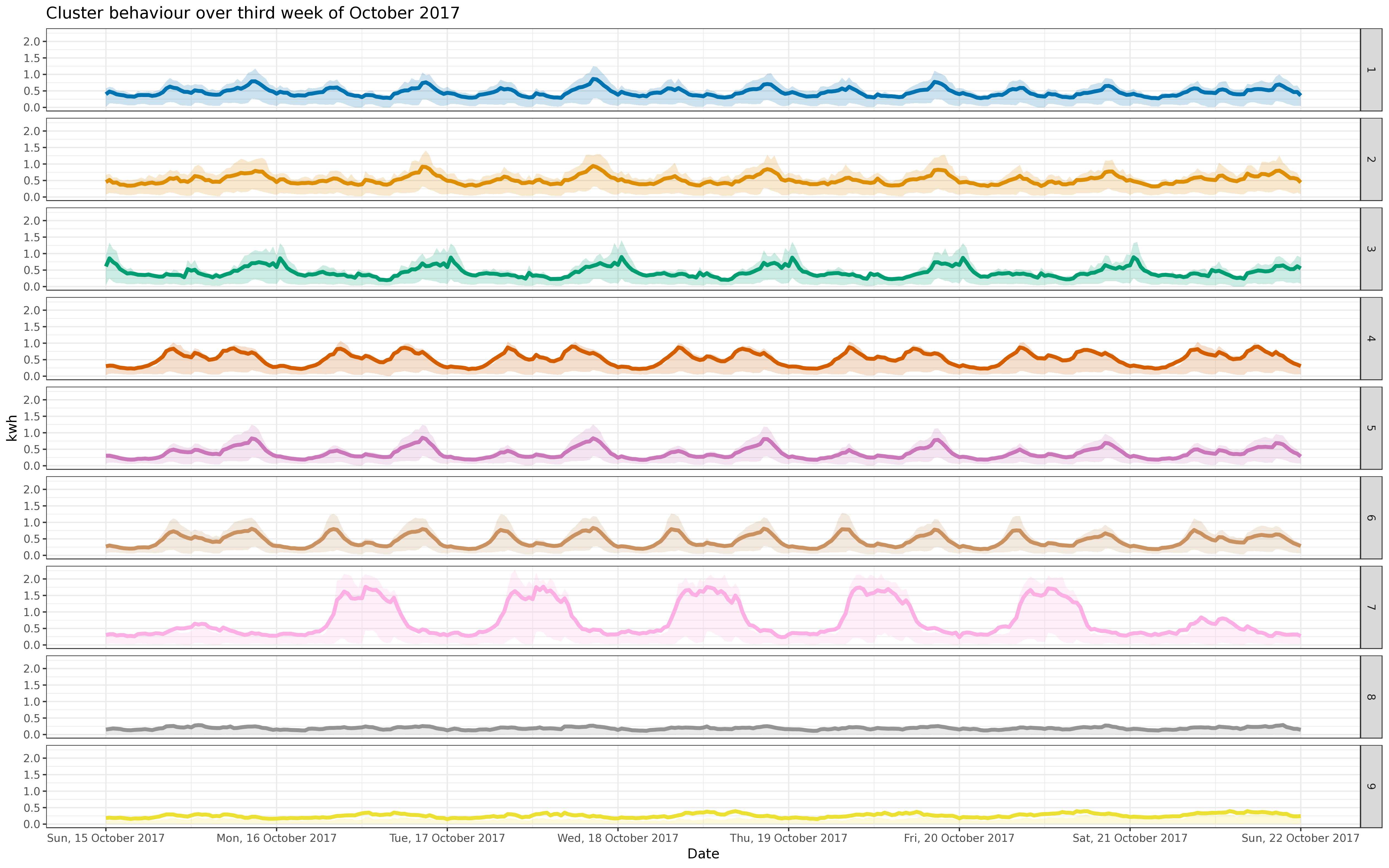
BIN
img/oct_fre_5k.png
View File
{kind=link}